Benchmarking the Ninja build system
By David Röthlisberger. Comments welcome at david@rothlis.net.
Published 4 Nov 2016. Last updated 7 Nov 2016. This article is Creative Commons licensed.
Ninja is a build tool that claims to be much faster than good old Make. Ninja was originally created because a no-op build of the Chrome browser (where all the targets are already up to date) took 10 seconds with GNU Make; Ninja reportedly takes less than a second on the same codebase. Let’s get some measurements from a more controlled environment.
Conclusions
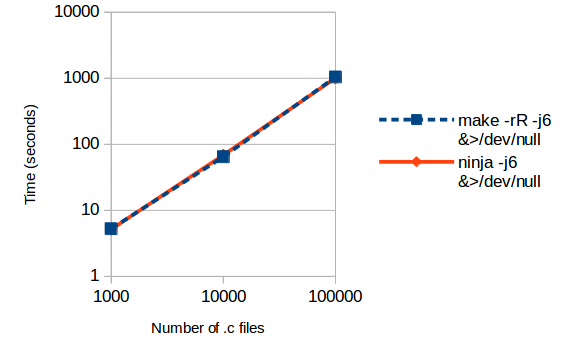
Fresh build
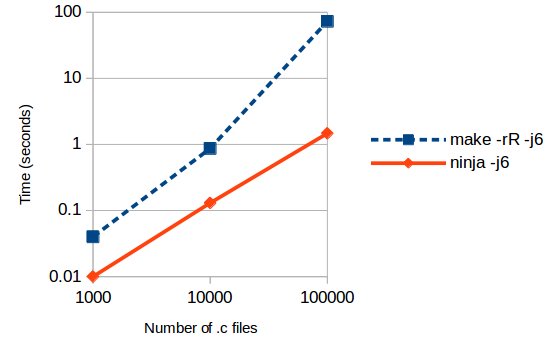
No-op build
For a project with 1,000 programs built from 10,000 C files and 10,000 header files, there is no significant difference in the duration of a fresh build. A no-op build takes less than a second with make (0.87s versus 0.13s with Ninja), probably not enough to really matter for interactive use.
For a much larger project (10,000 programs, 100,000 C files and 100,000 header files) there is a significant difference in a no-op build: 73s for Make versus 1.5s for Ninja. Make spends 98% of that time processing the 100,000 compiler-generated “.d” files that are used for tracking implicit dependencies on header files.
These differences will only matter for the very largest of projects (but I only tested on Linux – I wonder if the differences on Windows might be more pronounced).
Note that Ninja is actually doing more than Make in these tests: Ninja tracks the command-line used to build each target, and it will rebuild if the command changes, even if the dependencies didn’t change. It isn’t clear how best to implement this in pure Make, so I didn’t benchmark an equivalent Make-based feature.
I imagine that Make could be made as performant as Ninja by implementing specialised handling of implicit dependencies using a local file as a database, like Ninja does. Similarly, Make could be made to track the commands used to build each target – implementing this support manually in your Makefiles by various means might be a large source of slow-down for even much smaller projects. So far, Make has never used any metadata other than the timestamps provided by the filesystem, so I don’t know if such an approach would be palatable to the GNU Make maintainers.
Ninja builds things in the order they’re listed in the build file (dependencies permitting). Make does try to build depth-first, but it seems to push the targets to the end of a queue if it needed to build their prerequisites first, so it ends up building the leaf targets at the very end (it leaves all the linking steps until all the object files have been compiled, instead of linking each executable as soon as its own dependencies are available). This seems like an optimisation opportunity for Make to reduce bottlenecks during parallel builds.
Test setup
Tup is an entirely unrelated build system that has some nice automated performance tests here. I’ve used those scripts to generate 3 projects with 1k, 10k and 100k C files (plus 1k, 10k and 100k header files, respectively) spread across a number of directories. Each C file includes 7 header files. Out of every 10 C files we build an executable program. For more details on the test setup see Make vs Tup.
I generated a Makefile and a Ninja file in each of the 3 projects with the following “configure” script. Note that both versions are non-recursive, and they both use the standard technique for tracking header-file dependencies, so if a header file changes, any C files that include it will be re-compiled. One big difference between the two versions is that the Makefile won’t detect changes to the compilation command line (for example if we add some compiler flags, or we remove some input files in the linker command) whereas Ninja tracks each command automatically.
#!/bin/bash -e
cd "$(dirname "$0")/$1"
rm -f Makefile build.ninja
make() { echo "$*" >> Makefile; }
ninja() { echo "$*" >> build.ninja; }
progs=$(find . -name '*.c' | xargs -n1 dirname | sort | uniq |
sed 's,^\./,,' | sed 's,$,/prog,' | tr '\n' ' ')
make "all: $progs"
make '%.o: %.c'
make $'\tgcc -MMD -I. -c $< -o $@'
ninja "build all: phony $progs"
ninja 'default all'
ninja 'rule cc'
ninja ' command = gcc -MMD -MF $out.d -I. -c $in -o $out'
ninja ' depfile = $out.d'
ninja ' deps = gcc'
ninja 'rule link'
ninja ' command = gcc -o $out $in'
for f in $progs ; do
d=$(dirname $f)
objs=$(ls $d/*.c | sed 's/\.c$/.o/' | tr '\n' ' ')
make "$d/prog: $objs"
make $'\tgcc -o $@ $^'
ninja "build $d/prog: link $objs"
for o in $objs; do
make "-include ${o%.o}.d"
ninja "build $o: cc ${o%.o}.c"
done
done
For each measurement I took the minimum of three consecutive runs.
I ran the tests on a 2014 MacBook Pro with dual-core Intel Core i7-4578U processor, solid-state hard drive and 16GB of RAM, running Ubuntu 16.04 with GNU Make 4.1 and Ninja 1.6.0.
Ensuring the Make benchmark is valid
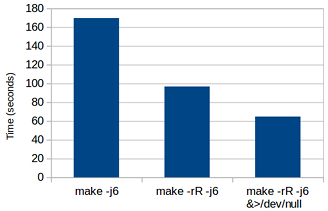
Fresh build with GNU Make
(on project with 10,000 .c files)
GNU Make has a huge number of built-in rules, and it will check each file in the build graph against each rule. You can disable these rules with the -r and -R command line flags – it makes a huge difference to performance. Note that before version 4.0, setting -rR in the MAKEFLAGS variable inside your Makefile didn’t work (you had to specify them on the command line).
Ninja runs several build jobs in parallel, by default. Make requires an explicit flag to enable parallelism. In all these results I have used -j6 for both Make and Ninja (6 is the default value that Ninja chooses on my system).
Make’s output tends to be a bit noisier than Ninja’s, so the performance measurements may be unduly impacted by IO to the terminal, especially with an artificial test-case like this where the actual compilation & linking is trivial. So for fresh builds I have redirected all output to /dev/null, except where otherwise noted.
Results
| Fresh build | ||
|---|---|---|
| # of .c files | Make | Ninja |
| 1,000 | 5.3s | 5.2s |
| 10,000 | 65s | 69s |
| 100,000 | 17m24s | 16m56s |
| No-op build | ||
|---|---|---|
| # of .c files | Make | Ninja |
| 1,000 | 0.04s | 0.01s |
| 10,000 | 0.87s | 0.13s |
| 100,000 | 73s | 1.5s |
Note the logarithmic scales on both axes.
A fresh build takes roughly the same amount of time with Make or Ninja. As you’d expect, the time is dominated by the compilation processes. There’s a fair bit of variation from one test-run to the next (the figures shown here are the shortest time out of 3 runs) so I wouldn’t read too much into the 4-second difference (6%) on the middle row or the 28-second difference (3%) on the bottom row.
On average the Make builds were 3m44s slower than Ninja (22% slower) on the largest project. I don’t know why. Maybe it was bad luck in my sampling. I did notice that Make left all the linking to the end, whereas Ninja linked each program as soon as its dependencies were built. Ninja tries to build things in the order they’re listed in the build file, whereas Make seems to push targets to the end of a queue if it needed to build their prerequisites first. I don’t know if this could explain the difference in average build times, perhaps due to higher resource usage by the linker leading to less effective parallelisation – but then why was the build just as fast as Ninja that one time?
For no-op builds, it looks like Ninja is roughly an order of magnitude faster than Make for every order of magnitude increase in the number of source files.
On the largest project (where a no-op build with Make is taking 70 to 100 seconds) Make is spending 98% of its time processing the 100,000 “.d” files with the header dependencies. I know this because if I delete them all, running Make only takes 2.4 seconds (now that we’ve deleted those files, Make won’t notice if we change a header file, so this isn’t a viable optimisation strategy). In case you’re wondering, Ninja stores the header dependency information in a binary file stored at the build root.
Processing the “.d” files doesn’t affect the time of the “fresh build” benchmark because there are no “.d” files to process. These are generated by the first build; if they don’t exist when Make starts up, Make doesn’t care because we used -include with a dash to ignore missing files. (If you need to build the target file anyway, because it has never been built before, then you don’t need to know the list of implicit dependencies.)
Incidentally, Ninja has a debug mode that will tell you where it spends its time:
$ touch src/21.c; ninja -d stats
[1/2] cc src/21.o
[2/2] link src/prog
metric count avg (us) total (ms)
.ninja parse 1 37433.0 37.4
canonicalize str 32003 0.1 3.5
canonicalize path 32011 0.1 1.9
lookup node 62011 0.1 8.2
.ninja_log load 1 8968.0 9.0
.ninja_deps load 1 16501.0 16.5
node stat 31001 1.1 34.6
StartEdge 3 286.0 0.9
FinishCommand 2 89.5 0.2
path->node hash load 0.63 (31001 entries / 49157 buckets)Do these results matter?
At 20k C & header files, the difference between Make and Ninja for a no-op build is less than a second. Do real projects get much larger than this?
- LLVM and Clang: 6,500 and 9,700 source files, respectively.1 Building Clang runs 2,500 build steps.2
- Chromium: 50,000 build steps2 (20x the size of a Clang build).
- Linux kernel: 50,000 source files.1
I wonder if the differences on Windows might be more pronounced at smaller project sizes.
- As reported by “
sloccount --filecount .” - As reported (by Ninja) in the logs from a recent build. See https://groups.google.com/d/msg/ninja-build/OzbcnD3wxIA/qFTInQw8CgAJ